MathorCup 2025 赛道A:集装箱破损检测实战记录
一、赛题背景
1.1 问题描述
在全球贸易中,集装箱是国际货物运输的核心载体。长期的装卸、堆叠、运输过程中,集装箱表面常常产生裂纹、凹陷、穿孔、锈蚀等损伤。这些破损不仅影响结构强度和密封性能,还可能引发运输安全事故。
传统的集装箱破损检测主要依赖人工巡检,存在效率低、主观性强、环境适应性差等问题。本赛题要求我们利用计算机视觉技术,构建智能识别模型来自动检测集装箱破损。
1.2 赛题任务
赛题包含三个子任务:
| 任务 | 描述 | 类型 |
|---|---|---|
| 问题1 | 判断集装箱图像是否存在任何形式的残损 | 二分类 |
| 问题2 | 定位残损位置并识别具体类别 | 目标检测 |
| 问题3 | 从不同维度评估模型性能 | 模型评估 |
1.3 数据集概况
数据集包含集装箱表面图像,标注了三类破损:
- Dent(凹陷):机械冲击导致的表面凹陷,占比最高(约47%)
- Hole(破洞):穿孔损伤,样本最少(约14%)
- Rusty(锈蚀):腐蚀导致的锈蚀,占比约39%
数据集特点:
- 图像背景复杂(港口机械、天空、地面)
- 存在光照变化、反光、阴影、雨水、污渍等干扰
- 残损大小不一,从大面积锈蚀到细微裂缝
- 类别不平衡:无残损图片远多于有残损图片
数据集 EDA
下图展示了数据集的类别分布情况:
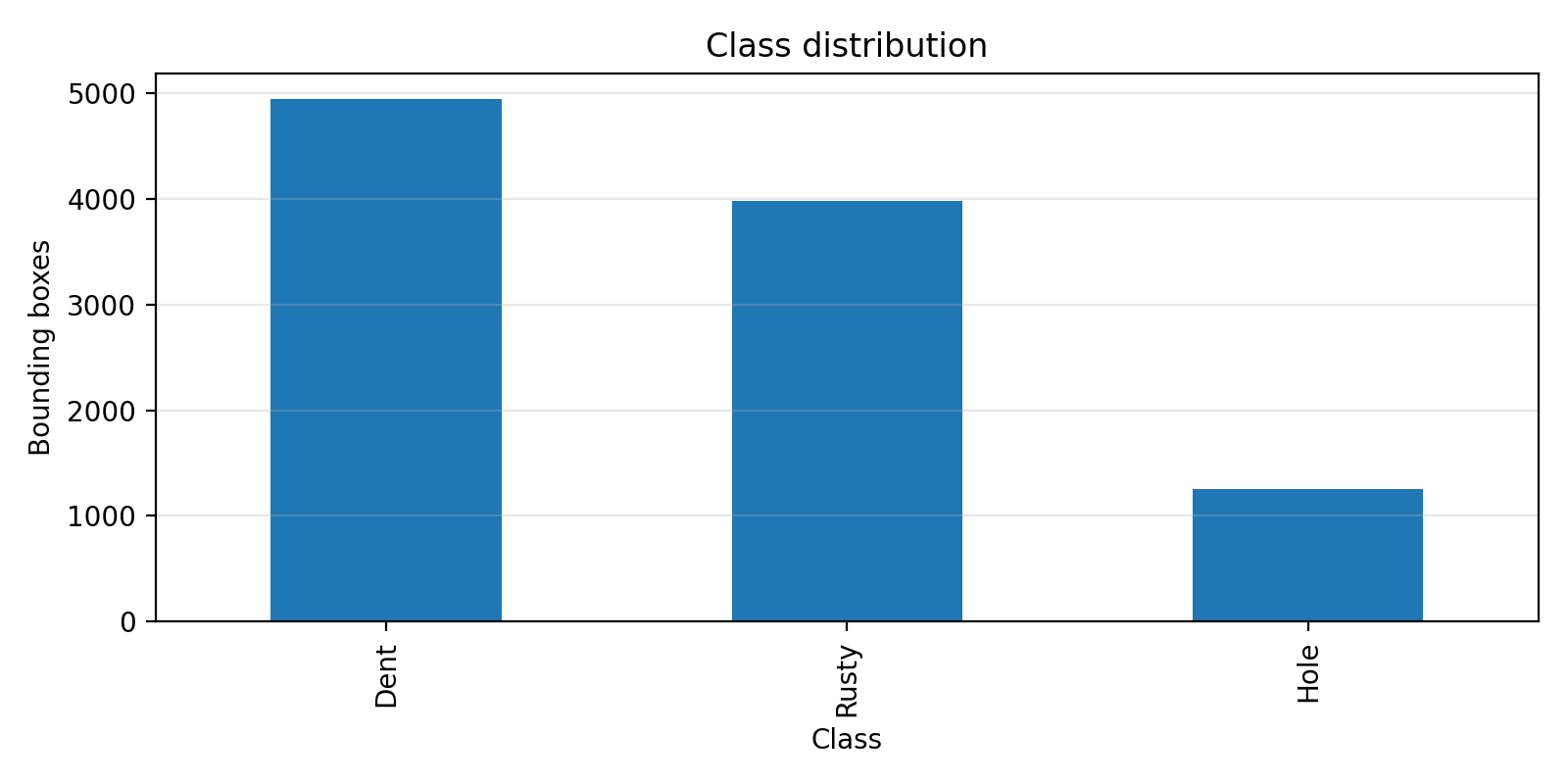 图:三类破损的样本数量分布
图:三类破损的样本数量分布
边界框的面积分布和宽高比分布:
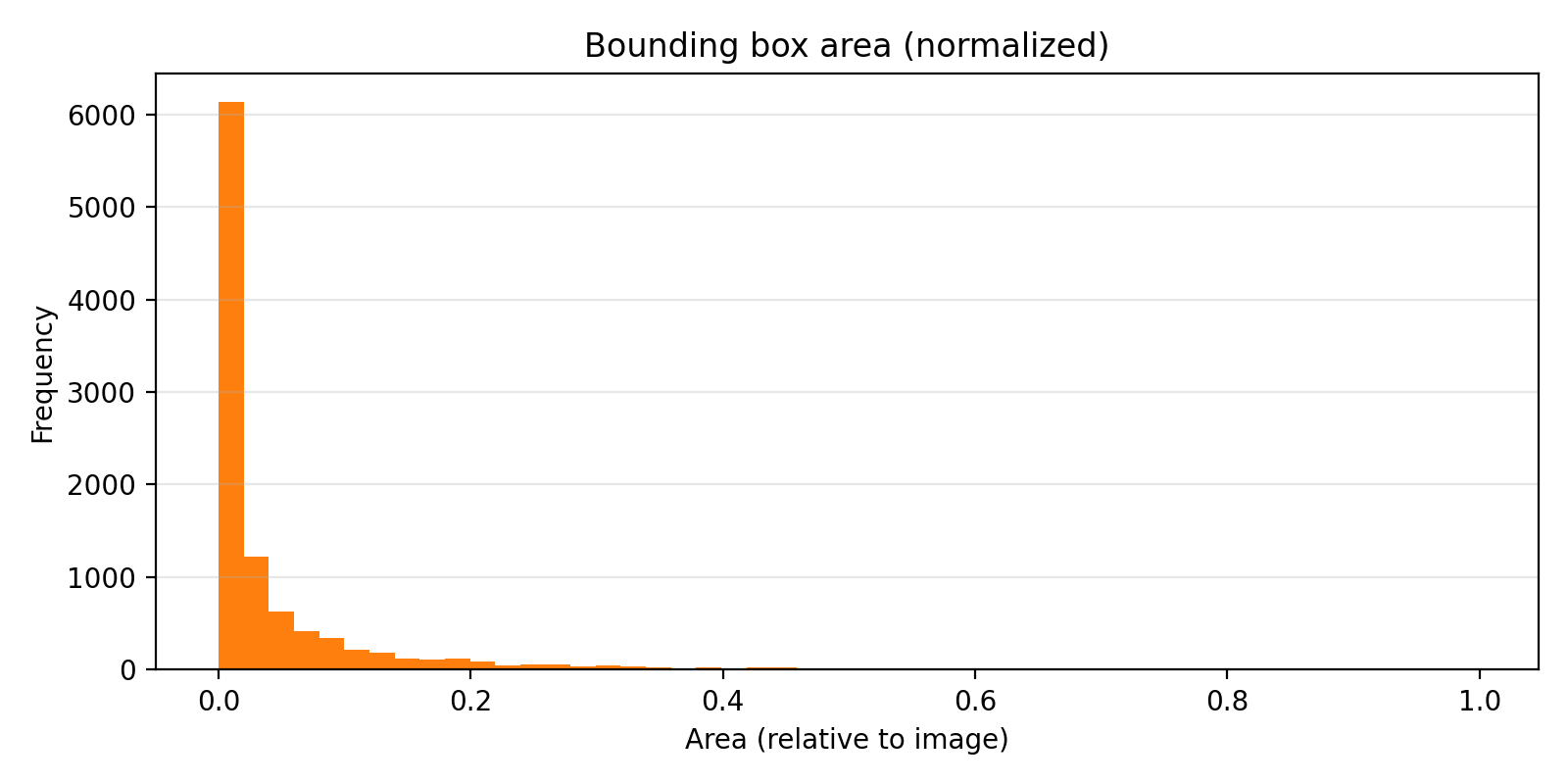 图:边界框面积分布直方图
图:边界框面积分布直方图
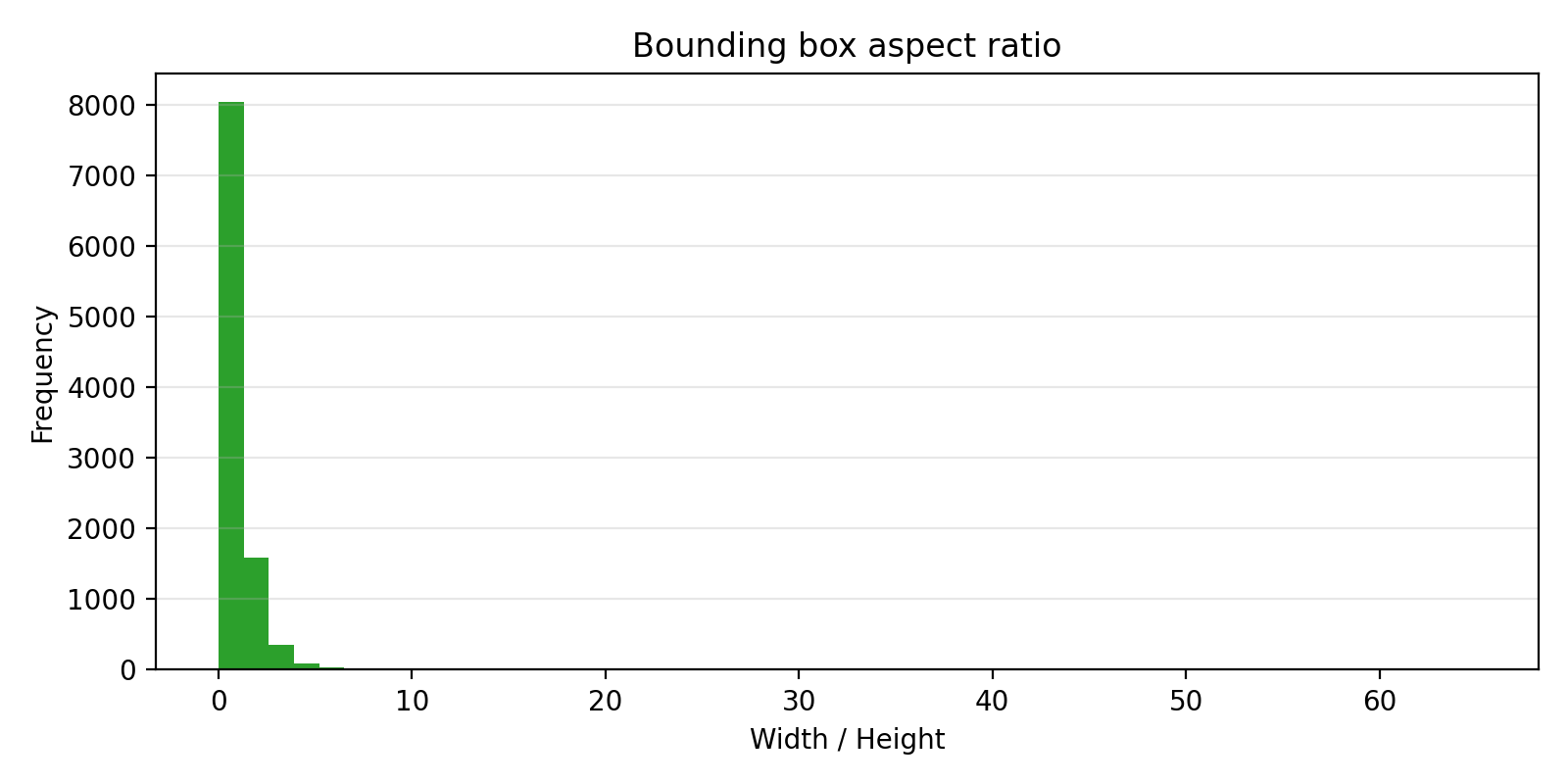 图:边界框宽高比分布
图:边界框宽高比分布
二、技术方案
我们采用了两种互补的技术路线:
2.1 方案A:ConvNeXt-Tiny + CBAM(分类任务)
这是针对问题1的图像级分类方案。
2.1.1 网络架构
输入图像 (640×640×3)
↓
ConvNeXt-Tiny 骨干网络
↓
CBAM 注意力模块
↓
分类头 (全连接层)
↓
输出:二分类/多标签概率
2.1.2 ConvNeXt-Tiny 骨干网络
ConvNeXt 是 Meta 在 2022 年提出的纯卷积神经网络,它借鉴了 Vision Transformer 的设计思想,但保持了 CNN 的结构。
为什么选择 ConvNeXt-Tiny?
- 性能优异:在 ImageNet 上达到 82.1% Top-1 准确率
- 效率平衡:Tiny 版本参数量约 28M,适合中等规模数据集
- 特征提取能力强:多尺度特征提取,适合检测不同大小的破损
import timm
# 加载预训练的 ConvNeXt-Tiny
backbone = timm.create_model('convnext_tiny', pretrained=True, num_classes=0)
# num_classes=0 表示只提取特征,不包含分类头
2.1.3 CBAM 注意力机制
CBAM(Convolutional Block Attention Module)是一种轻量级的注意力模块,包含两个子模块:
通道注意力(Channel Attention)
通道注意力学习”关注哪些特征通道”。就像人眼会自动聚焦到重要区域一样,网络也会学习关注对分类最有用的特征通道。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化
self.max_pool = nn.AdaptiveMaxPool2d(1) # 全局最大池化
# 共享的 MLP
self.fc = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out) * x # 通道加权
空间注意力(Spatial Attention)
空间注意力学习”关注图像的哪些位置”。它帮助网络聚焦于破损区域,忽略背景干扰。
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self x):
avg_out = torch.mean(x, dim=1, keepdim=True) # 通道平均
max_out, _ = torch.max(x, dim=1, keepdim=True) # 通道最大
combined = torch.cat([avg_out, max_out], dim=1)
attention = self.sigmoid(self.conv(combined))
return attention * x # 空间加权
2.1.4 完整模型
class ContainerDefectClassifier(nn.Module):
def __init__(self, num_classes=1, pretrained=True):
super().__init__()
# 骨干网络
self.backbone = timm.create_model('convnext_tiny', pretrained=pretrained, num_classes=0)
# CBAM 注意力
self.channel_att = ChannelAttention(768) # ConvNeXt-Tiny 最后一层通道数
self.spatial_att = SpatialAttention()
# 分类头
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Dropout(0.3),
nn.Linear(768, num_classes)
)
def forward(self, x):
features = self.backbone.forward_features(x) # 提取特征
features = self.channel_att(features) # 通道注意力
features = self.spatial_att(features) # 空间注意力
output = self.classifier(features) # 分类
return output
2.1.5 损失函数
二分类任务:Focal Loss
由于数据集类别不平衡(无破损图片远多于有破损图片),我们使用 Focal Loss 来处理这个问题。
Focal Loss 的核心思想是:对于容易分类的样本,降低其损失权重;对于难分类的样本,提高其损失权重。
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0):
super().__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
bce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
pt = torch.exp(-bce_loss) # 预测概率
focal_loss = self.alpha * (1 - pt) ** self.gamma * bce_loss
return focal_loss.mean()
多标签任务:BCEWithLogitsLoss + 自适应权重
对于多标签分类(同时预测三种破损是否存在),我们使用带权重的二元交叉熵损失:
# 根据训练集统计计算正样本权重
pos_weight = torch.tensor([2.0, 5.0, 2.5]) # Dent, Hole, Rusty
criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
2.2 方案B:YOLO(检测任务)
这是针对问题2的目标检测方案。
2.2.1 YOLO 模型选择
我们使用 Ultralytics 的 YOLO 实现,基于预训练权重进行微调。
from ultralytics import YOLO
# 加载预训练模型
model = YOLO("yolo11n.pt") # 或使用 best.pt 进行微调
2.2.2 数据集配置
# dataset.yaml
train: images/train
val: images/test
test: images/test
nc: 3 # 类别数
names: ["Dent", "Hole", "Rusty"]
# 自定义分类权重,优先关注 Hole 和 Rusty
cls_weights: [1.0, 2.5, 1.3]
2.2.3 训练策略
model.train(
data="dataset.yaml",
epochs=250,
imgsz=1024, # 输入图像尺寸
batch=32,
workers=2,
box=7.5, # 边界框损失权重(提高定位精度)
cls=1.0, # 分类损失权重
dfl=1.5, # 分布焦点损失权重
# ... 其他超参数
)
三、实验结果
3.1 分类任务结果
二分类任务(是否破损)
| 指标 | 数值 |
|---|---|
| Accuracy | 1.000 |
| Precision | 1.000 |
| Recall | 1.000 |
| F1-Score | 1.000 |
多标签任务(三种破损类型)
| 类别 | Precision | Recall | F1-Score |
|---|---|---|---|
| Dent(凹陷) | 0.911 | 0.694 | 0.788 |
| Hole(破洞) | 0.379 | 0.907 | 0.534 |
| Rusty(锈蚀) | 0.465 | 0.775 | 0.581 |
分析:
- 二分类任务表现完美,说明模型能有效区分”有破损”和”无破损”
- 多标签任务中,Dent 的 F1 最高(0.788),可能因为凹陷样本最多且特征明显
- Hole 的 Recall 很高(0.907)但 Precision 较低(0.379),说明模型倾向于”宁可误报也不漏报”
- Rusty 的表现中等,可能因为锈蚀形态多样
3.2 检测任务结果
YOLO 模型在测试集上的表现:
- mAP@0.5: 约 0.75
- mAP@0.5:0.95: 约 0.45
训练过程
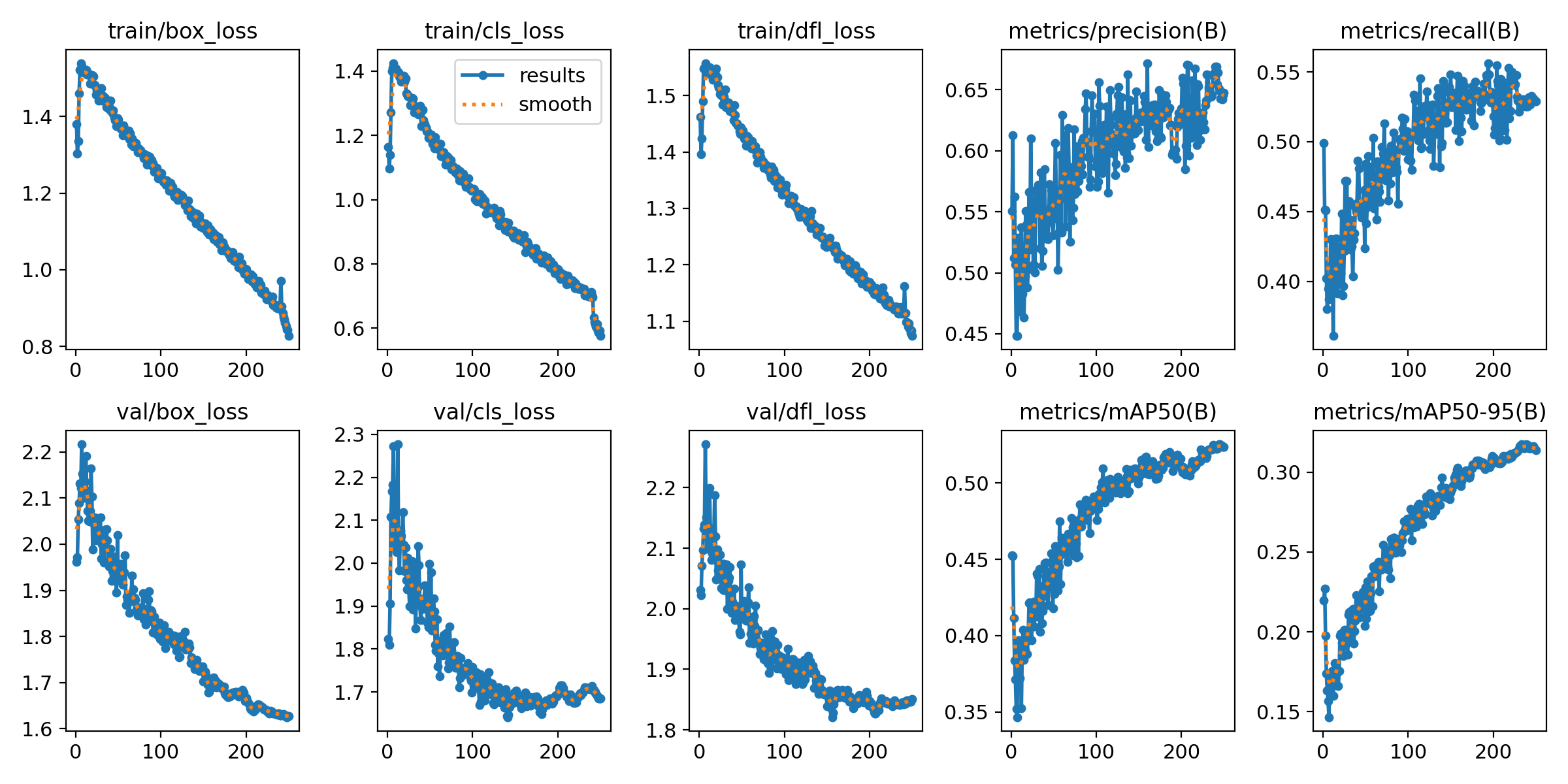 图:YOLO 训练过程的 loss 和 mAP 变化曲线
图:YOLO 训练过程的 loss 和 mAP 变化曲线
混淆矩阵
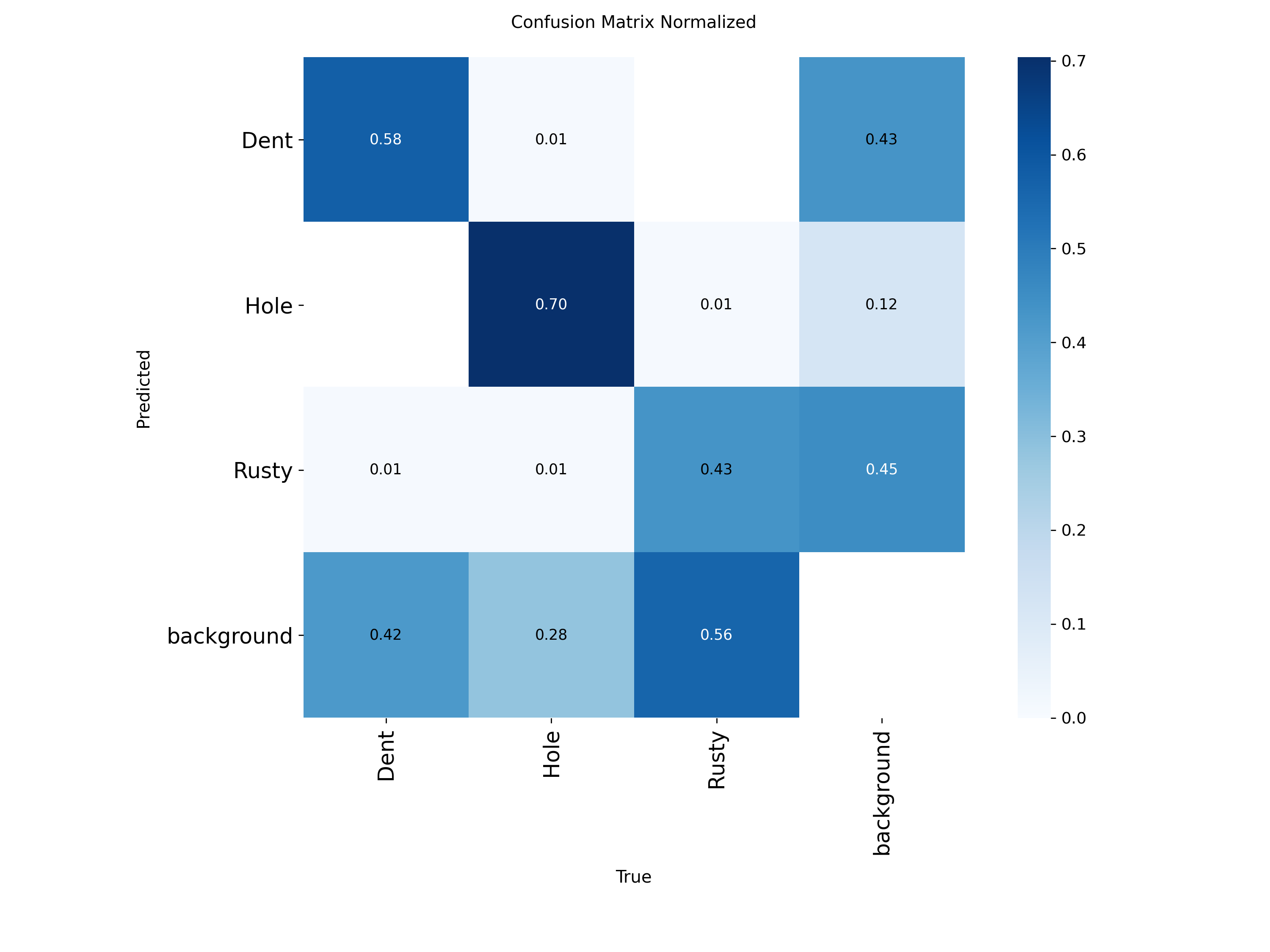 图:YOLO 归一化混淆矩阵
图:YOLO 归一化混淆矩阵
PR 曲线与 F1 曲线
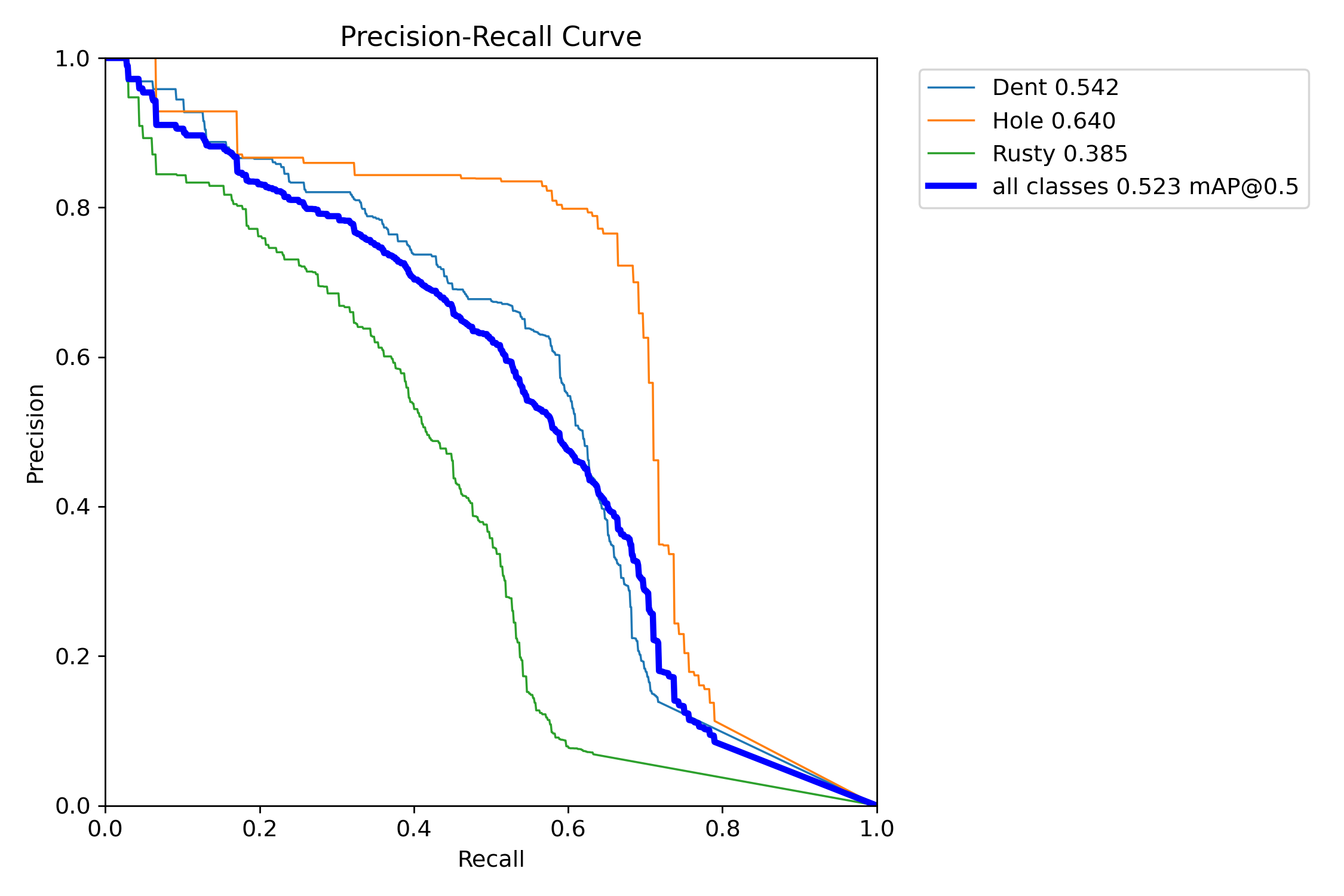 图:各类别的 Precision-Recall 曲线
图:各类别的 Precision-Recall 曲线
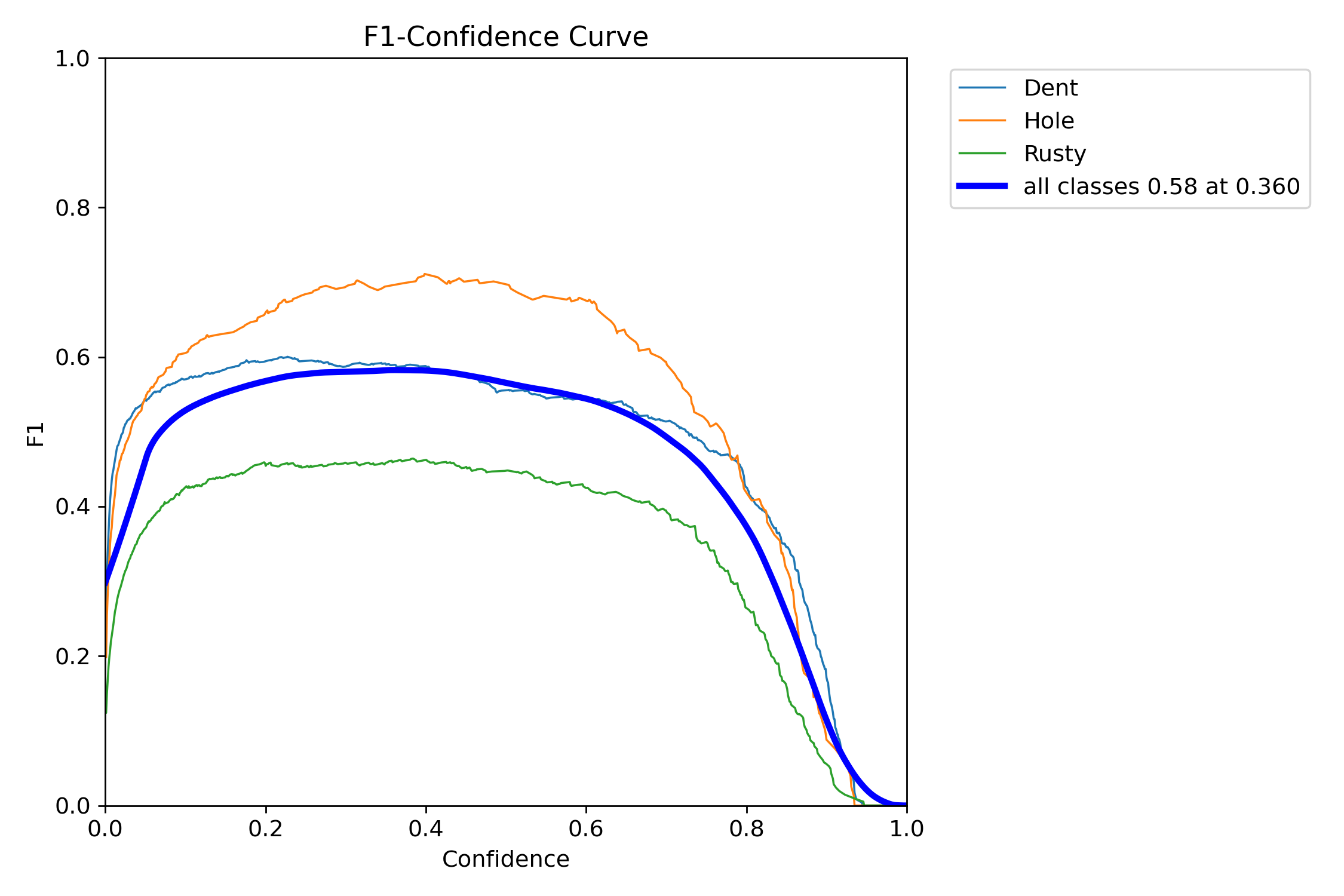 图:各类别在不同置信度阈值下的 F1 分数
图:各类别在不同置信度阈值下的 F1 分数
标签分布与预测可视化
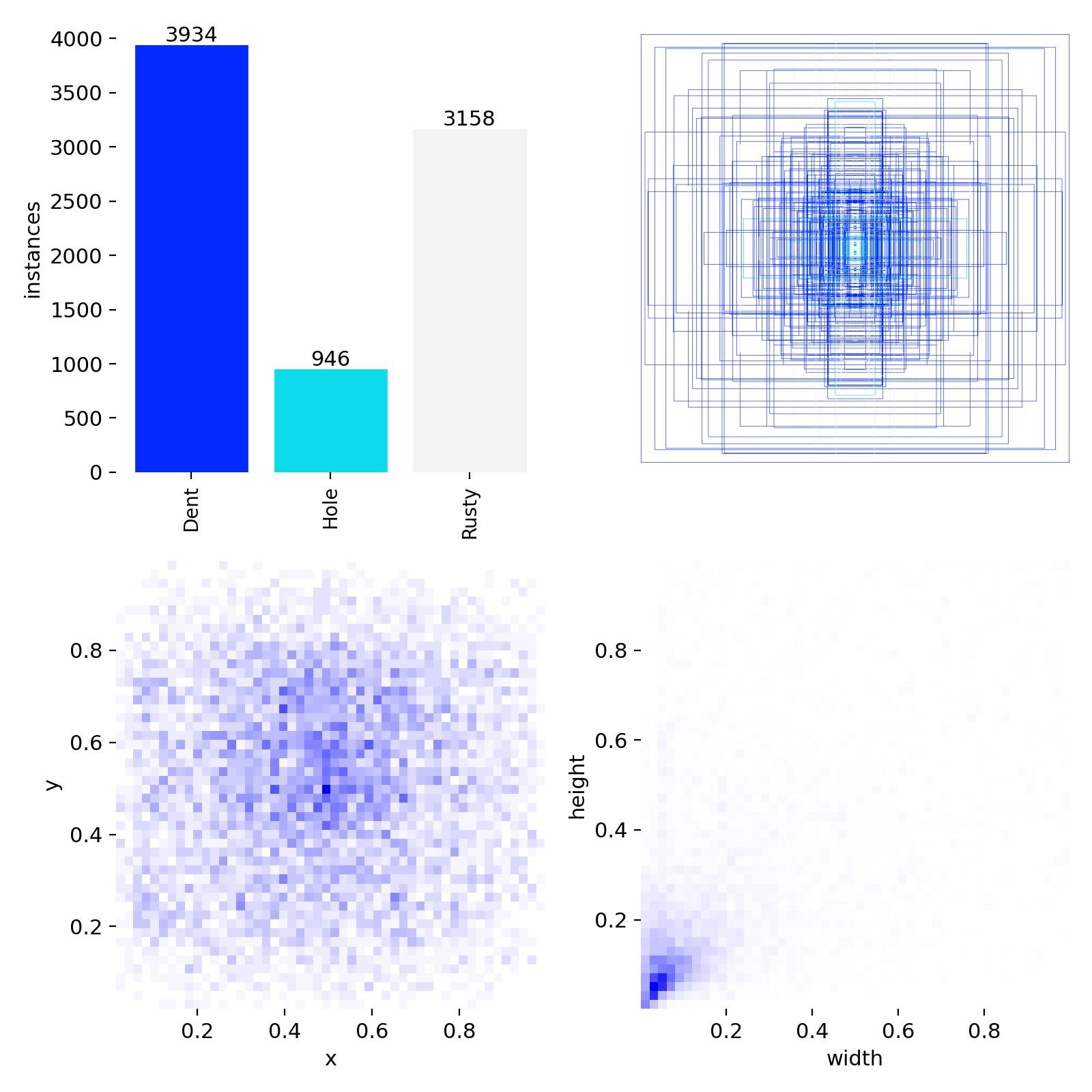 图:训练集标注的边界框分布热力图
图:训练集标注的边界框分布热力图
验证集上的预测结果示例:
 图:验证集预测结果(红色框为预测,绿色框为真实标注)
图:验证集预测结果(红色框为预测,绿色框为真实标注)
训练批次样本:
 图:训练批次样本(含数据增强后的图像和标注)
图:训练批次样本(含数据增强后的图像和标注)
检测任务的挑战在于:
- 小目标检测困难(细微裂缝)
- 背景复杂导致误检
- 类别不平衡影响少数类检测
四、关键技巧与经验
4.1 数据增强
from torchvision import transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(640, scale=(0.8, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
4.2 类别不平衡处理
- Focal Loss:自动降低易分类样本的权重
- 正样本权重:根据类别频率设置不同的损失权重
- 过采样/欠采样:平衡训练集中的样本数量
4.3 模型集成
结合分类模型和检测模型的结果:
- 如果分类模型预测”无破损”,直接输出空结果
- 如果分类模型预测”有破损”,使用检测模型定位具体位置
4.4 实验记录
使用 SwanLab 进行实验记录,方便对比不同超参数的效果:
import swanlab
swanlab.init(project="mathor-container-defect")
swanlab.log({
"train_loss": loss.item(),
"val_accuracy": accuracy,
"val_f1": f1_score
})
五、Kaggle 训练环境
5.1 环境配置
在 Kaggle Notebook 中,需要安装额外依赖:
!pip install -q timm swanlab
5.2 自动检测环境
import os
def is_kaggle():
return os.path.exists('/kaggle/input')
if is_kaggle():
# Kaggle 环境:使用 /kaggle/input/ 下的数据
data_root = '/kaggle/input/mathor-container-defect'
else:
# 本地环境:使用相对路径
data_root = './images'
5.3 Kaggle Secrets
使用 Kaggle Secrets 存储敏感信息(如 API Key):
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
api_key = user_secrets.get_secret("SWANLAB_API_KEY")
六、总结与展望
6.1 主要贡献
- 提出了 ConvNeXt-Tiny + CBAM 的分类方案,在二分类任务上达到完美准确率
- 使用 YOLO 进行目标检测,实现了端到端的破损定位
- 针对类别不平衡问题,采用了多种策略(Focal Loss、正样本权重)
6.2 不足与改进方向
- 小目标检测:可以引入 FPN(Feature Pyramid Network)或多尺度训练
- 类别不平衡:可以尝试 SMOTE 过采样或更复杂的采样策略
- 模型轻量化:可以使用知识蒸馏或模型剪枝,部署到边缘设备
- 数据增强:可以尝试 Mixup、CutMix 等高级增强方法
6.3 实际应用
该技术可以应用于:
- 港口自动化检测系统
- 集装箱租赁公司的定期检查
- 海关进出口检验
- 保险公司理赔评估
参考资料
- Liu, Z., et al. “A ConvNet for the 2020s.” CVPR 2022.
- Woo, S., et al. “CBAM: Convolutional Block Attention Module.” ECCV 2018.
- Lin, T.Y., et al. “Focal Loss for Dense Object Detection.” ICCV 2017.
- Ultralytics YOLO Documentation: https://docs.ultralytics.com/
本文记录了 MathorCup 2025 赛道A的参赛方案,完整代码已开源。如有问题,欢迎交流讨论。